每经编辑 杜宇

虽然被OpenAI抢在前面发布了重磅新品演示,但谷歌后发制人,做到了OpenAI还没能做到的事,率先发布人工智能(AI)搜索引擎,捍卫搜索领域的王者地位,同时对垒OpenAI新发布的旗舰模型GPT-4o,以升级版的最强大AI模型Gemini迎战。
从北京时间5月15日凌晨1点开始,谷歌在山景城总部附近的海岸线圆形剧场,召开了长达两个小时的年度I/O开发者大会Keynote演讲。
与预期一致,谷歌的这场发布会基本都是在谈AI、AI、AI、AI和AI。根据发布会最后的官方统计,整场Keynote的演讲稿里总共提了120次AI。
谷歌CEO Sundar Pichai表示,谷歌所有的工作都围绕生成式AI模型Gemini来做,“我们希望每个人都能从Gemini所做的事中受益。”AI搜索正是Pichai提到的Gemini融入谷歌多种服务之一。
同时谷歌搜索也将具备多步骤推理能力,可以一次性处理带有多个限制条件的长问题,并支持“拍视频”搜索解决方案的新搜索形式。
另外以上下文窗口“长”闻名的Gemini 1.5 Pro大模型,在今年晚些时候将会把100万Tokens的窗口,进一步扩大至200万Tokens,拓展同步处理多模态信息的边界。而对于一些需要快速响应的场景,谷歌也推出了Gemini 1.5 Flash模型。今年2月刚刚问世的Gemma开源模型,也将在下个月迎来参数量更大的Gemma 2。在多模态领域,谷歌也发布了文生图工具Imagen 3、与Youtube&音乐家合作的“AI音乐沙盒”,以及最新的视频生成模型Veo。而多模态Gemini Nano模型也将在今年晚些时候登陆Pixel手机,这是在本地运行的机载模型。
值得注意的是,谷歌的发布会上也有一些与昨日OpenAI发布会“雷同”的地方——实时AI助手。从今年夏天开始,Gemini也将支持语音实时交互,同时今年晚些时候还将上线实时视频交互。未来几个月内,谷歌也将推出类似于GPTs的自定义AI助手功能,叫做Gems,能够与整套“谷歌全家桶”联动。
硬件方面,谷歌宣布了第六代TPU芯片Trillium,并透露能够在明年初用上英伟达最新的Blackwell架构GPU。另外,液冷、光缆等中国股民可能会感兴趣的题材也在发布会上出现。
谷歌称,推出号称有史以来最强大AI模型Gemini Advanced三个月内。从本周二起,谷歌在Gemini Advanced中加入新模型成员Gemini 1.5 Pro,称它拥有的上下文窗口在全球消费类聊天机器人中最长,窗口起始就有100万个token。Gemini 1.5 Pro将向150 多个国家地区的Gemini Advanced订阅者提供,支持超过35 种语言。
Pichai称,Gemini 1.5 Pro“提供了迄今为止所有基础模型中最长的上下文窗口。” 他介绍,Gemini 1.5 Pro将拥有200 万个token的上下文窗口,是当前模型100万个token窗口的两倍。

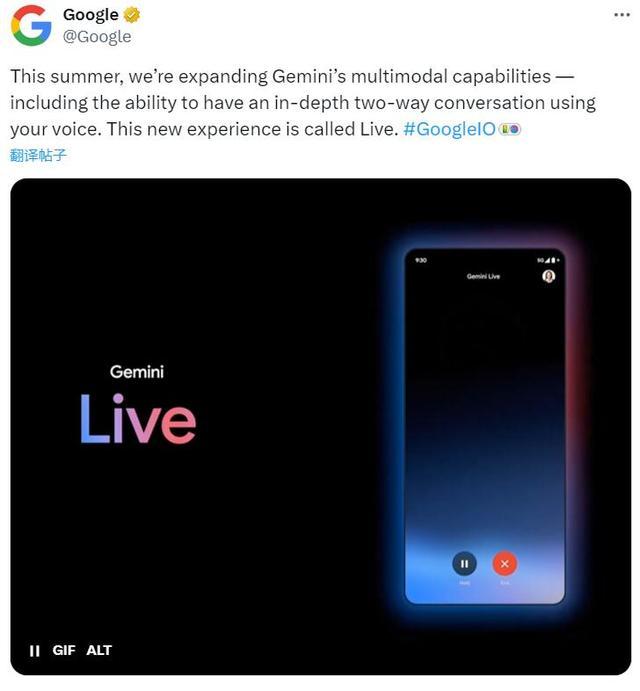
谷歌称,今年夏季将扩展 Gemini 的多模态功能,包括增加用语音进行深入双向对话的能力,该功能被称为 Live。通过 Gemini Live,用户可以与 Gemini 交谈,并可以从各种自然的声音中选择它回应的声音。 用户甚至可以按照自己的节奏说话,或者在回答过程中打断并澄清问题,就像在任何人类对话中一样。
谷歌称,今年夏季,将在Gemini Advanced 中添加新的旅行规划功能。借虑时间和空间方面物流的先进推理,Gemini将能够创建个性化的行程,节省用户的工作时间。
未来几周,谷歌将在Gemini Advanced中添加新的数据分析功能。用户只需上传电子表格,Gemini 就可以分析数据、制作图表,并更快地发掘见解。
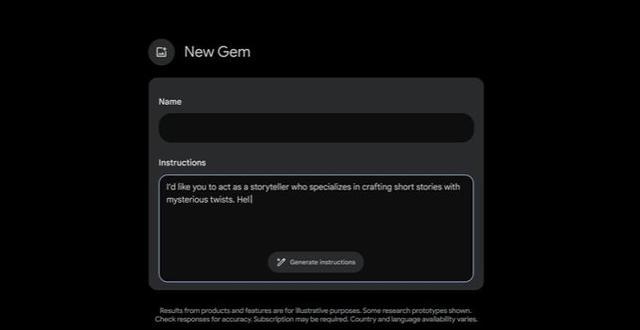
谷歌将推出被称为Gem的Gemini的定制版本。Gemini Advanced 订阅者将很快可以获得更个性化的体验,根据自己的需要创建Gemini,只需描述用户希望 Gem 做什么以及希望它如何响应,就可以让它化身健身伙伴、主厨帮手、编代码的拍档或者创意写作指南。

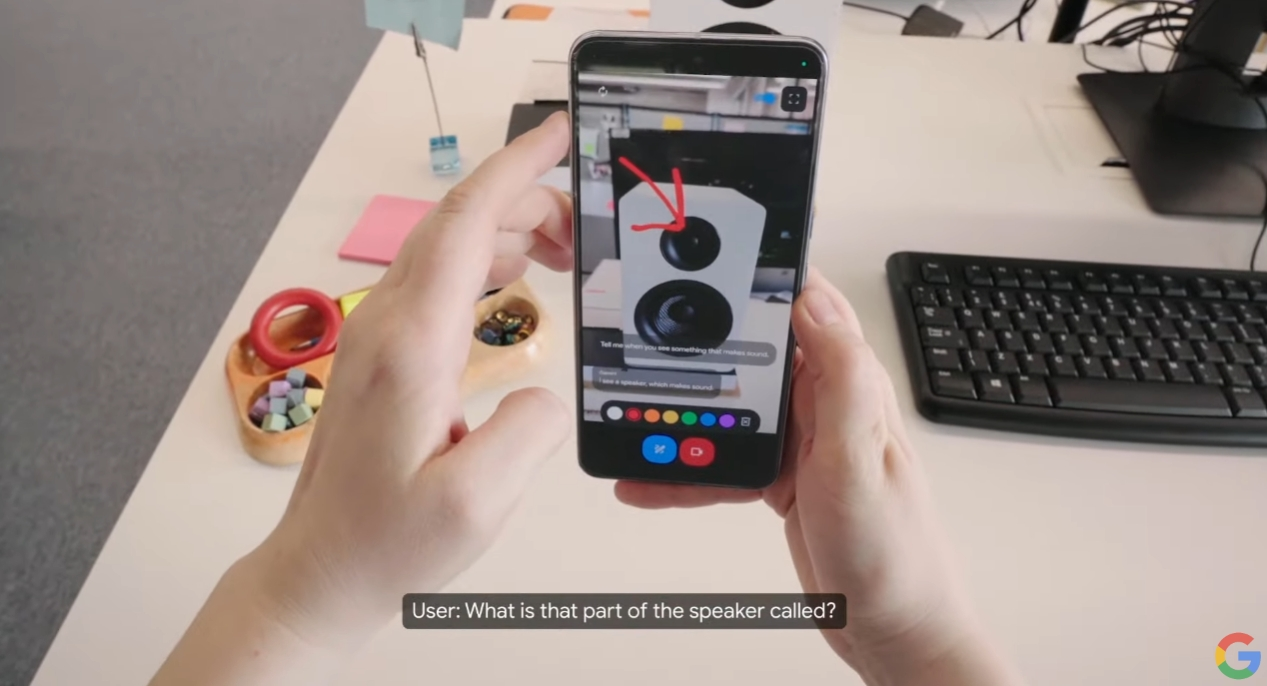
谷歌官宣推出新的多模态AI项目Project Astra,它可以为用户解释智能手机拍到的东西。在谷歌展示的视频中,只要将手机摄像头对准某个物体,Gemini就可以识别它,比如一个红苹果,还可以回答诸如镜头中什么东西是可以发声的这种问题。

谷歌称,将很快为模型Gemini Nano添加多模式功能。这意味着,用户的手机可以通过文本、图像、声音和口语,按照用户理解的方式理解世界。
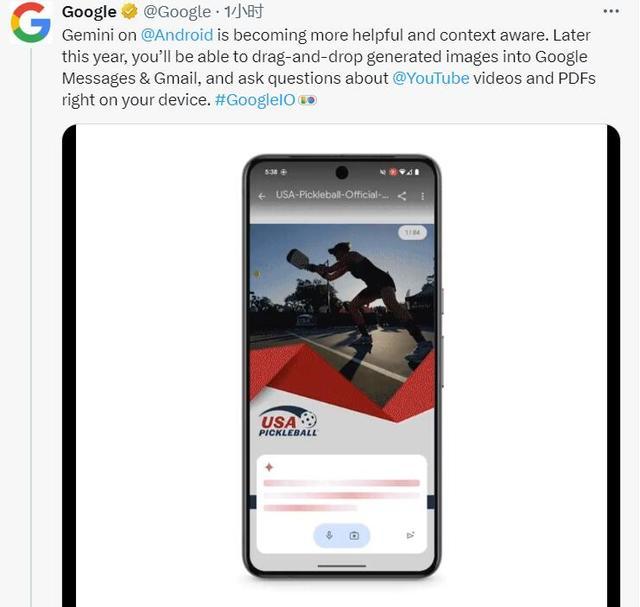
谷歌称,端侧安卓系统手机版的Gemini Nano将更有帮助,更有上下文的意识。今年,安卓手机的用户将可以将生成的图像拖放到Google Messages 和 Gmail 中,并可以直接在手机上提出有关YouTube视频和 PDF文件的问题,得到解答。
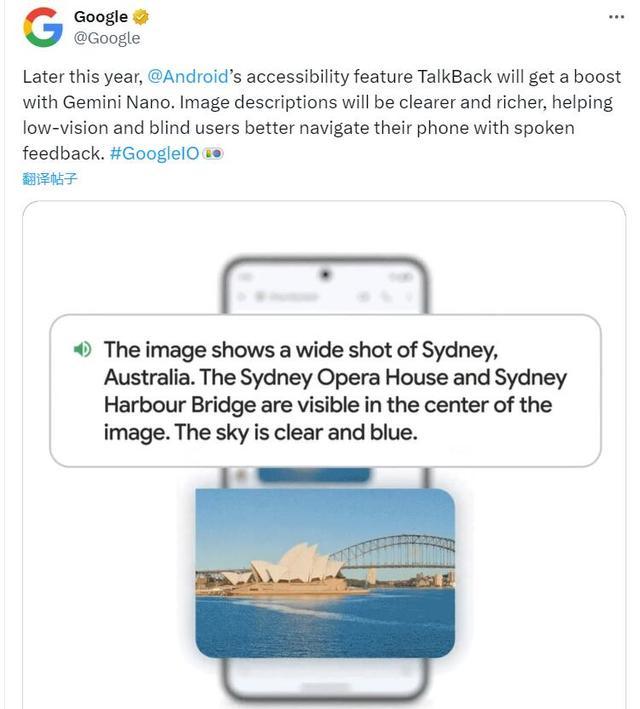
谷歌称,今年晚些时候,Gemini Nano的辅助功能TalkBack将增强。图像描述将更加清晰和丰富,帮助弱视用户和盲人用户通过语音反馈,更好地指示他们的手机。
发布会开始,Alphabet&谷歌CEO桑达尔·皮查伊登上舞台。

皮查伊表示,现在已经有超过150万开发者正在使用谷歌的人工智能Gemini,今天将展示一系列有关搜索、图片、工作套件、安卓系统等等与人工智能有关的案例。


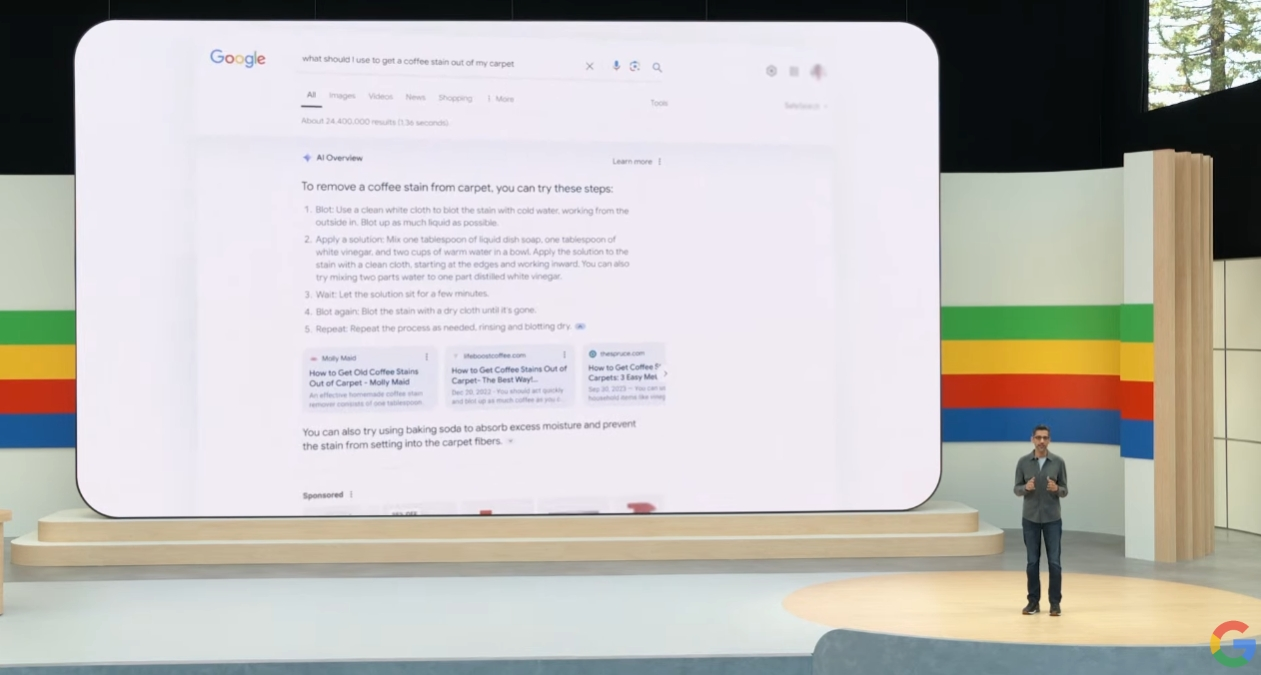
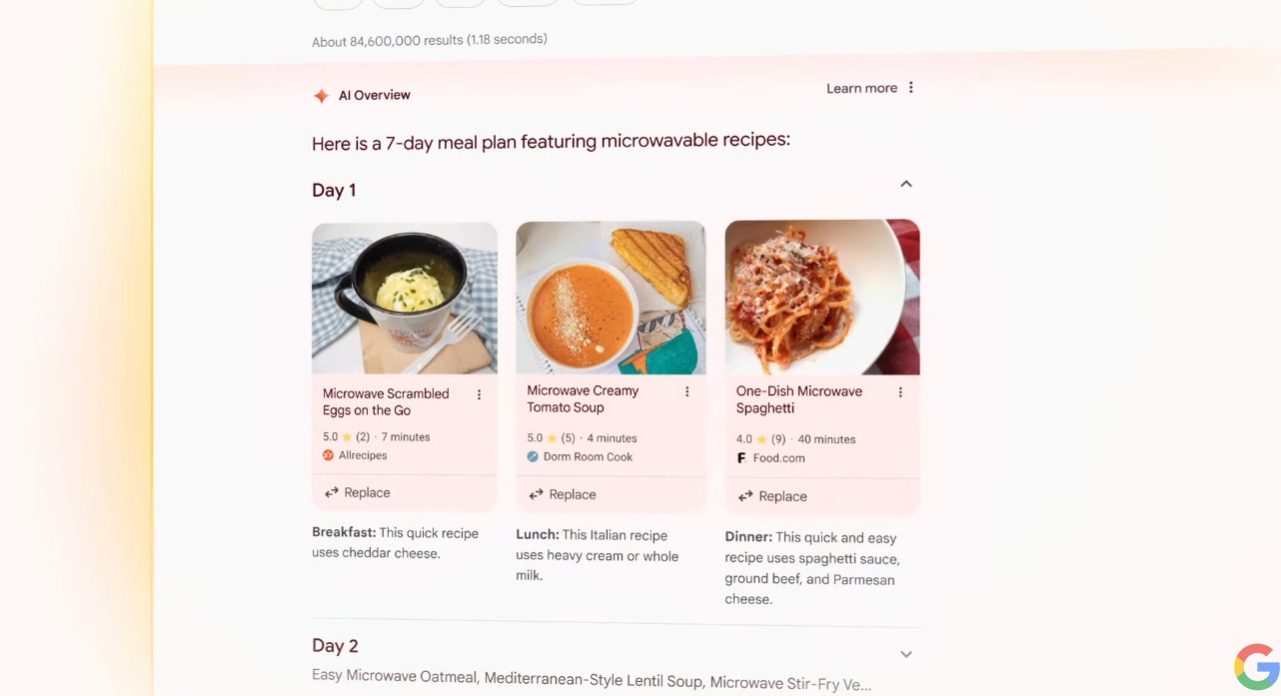
皮查伊宣布,能够总结谷歌搜索引擎结果的“AI概览”(AI Overviews)功能,将于本周在美国推出。

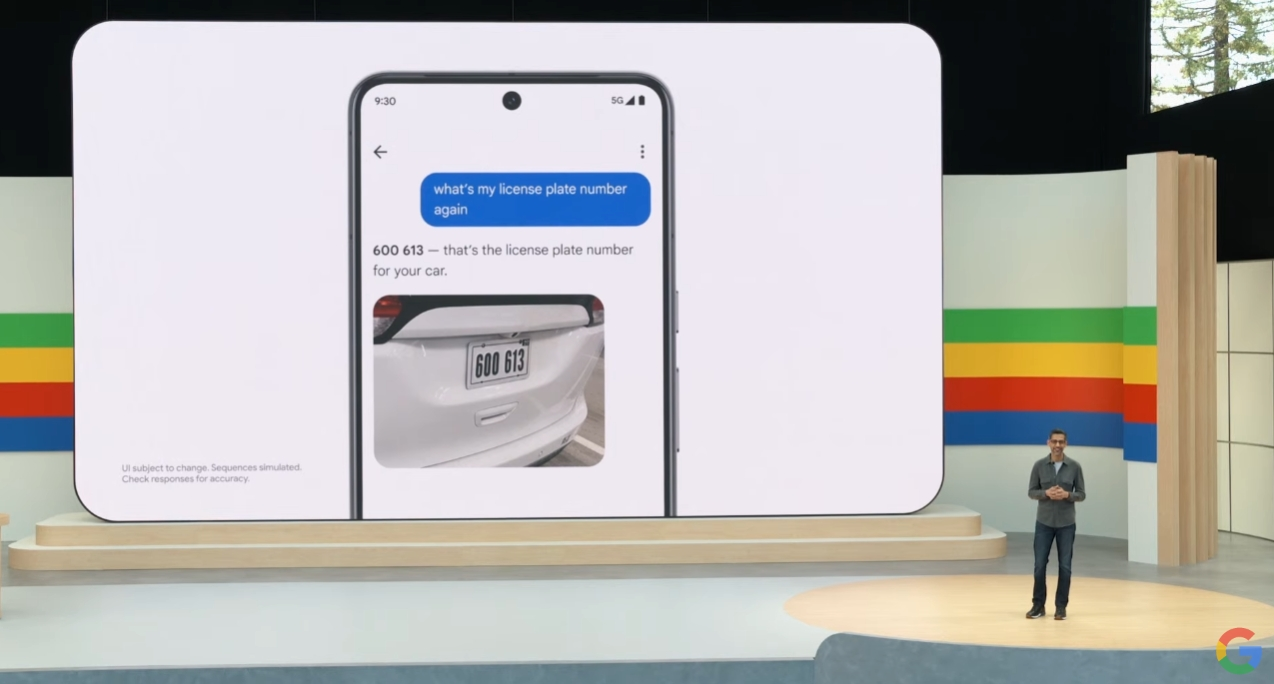
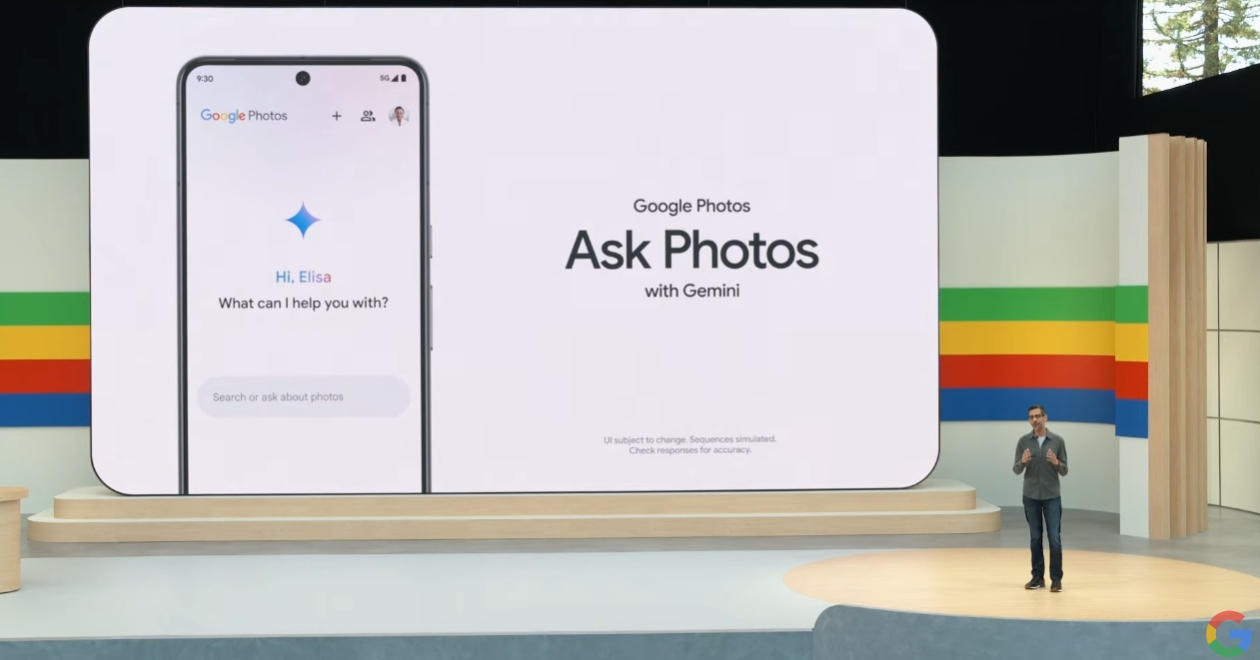
---基于Gemini支持,谷歌图片(Google Photos)将支持用户存储图片的AI搜索,例如“告诉我,我的车牌号码是多少?”——这个名为Ask Photos的功能将于今年夏天推出。
皮查伊宣布,最新版本的Gemini 1.5 Pro(在多项核心功能方面均较最初发布版本有所提高)现在向全球所有开发者开放。从今天开始,支持100万tokens上下文窗口的Gemini 1.5 Pro将在Gemini Advanced功能下向用户开放,支持35种语言。



谷歌同时面向开发者推出支持200万tokens的Gemini 1.5 Pro模型的预览,并表示最终的目标将是“无限上下文”。
谷歌AI业务总负责人、DeepMind的首席执行官杰米斯·哈萨比斯登台,宣布推出Gemini 1.5 Flash大模型。这个模型兼具速度与效率,和多模态推理能力,以及长达100万tokens的上下文窗口。开发者将能够申请体验200万tokens的上下文窗口的Gemini 1.5 Flash。



谷歌展示“未来的人工智能助手”——名为“Astra”的项目。哈萨比斯表示,这样的AI助手需要像人类一样理解这个动态且复杂的世界。需要记得住它看到的东西,这样才能理解对话并付诸于行动。同时它也得能积极主动接受教导,以及自然、无延迟地进行交流。在演示视频中,谷歌的AI助手能够通过摄像头视频,识别“什么东西能发出声音”、“现在身处何地”等指令。


谷歌宣布了一系列与图像、音乐、视频有关的生成式AI工具。包括文生图工具Imagen 3、与Youtube以及音乐家合作的“AI音乐沙盒”,以及最新的视频生成模型Veo。




其中最受关注的视频生成模型Veo,能够根据文字、图片和视频的提示,生成高质量1080p视频。

哈萨比斯离场,皮查伊重回舞台,发布第六代TPU芯片Trillium,较上一代芯片的算力表现翻4.7倍,云用户从今年下半年开始可以用上新芯片。同时谷歌云将在2025年初,用上英伟达的最新Blackwell架构GPU。


皮查伊开始介绍自家的AI超级计算机,比起用户自己买相同的硬件和芯片,谷歌的架构能使得效能翻倍,其中有部分功劳来自于液冷系统。皮查伊表示,谷歌部署液冷系统的数据中心已经达到1GW,而且还在不断增长中。



皮查伊表示,谷歌投资了200万英里的地面和海底光纤,比第二名的云服务商翻了十倍。液冷、光缆,应该都是股民们会感兴趣的东西。
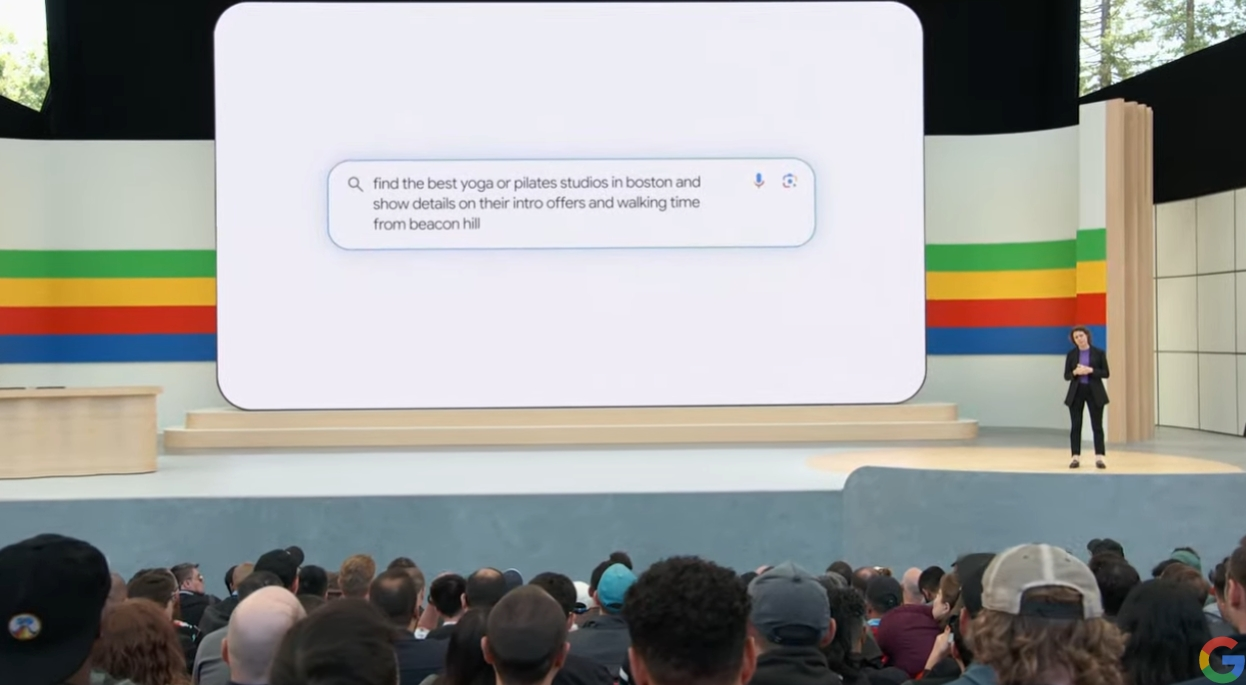
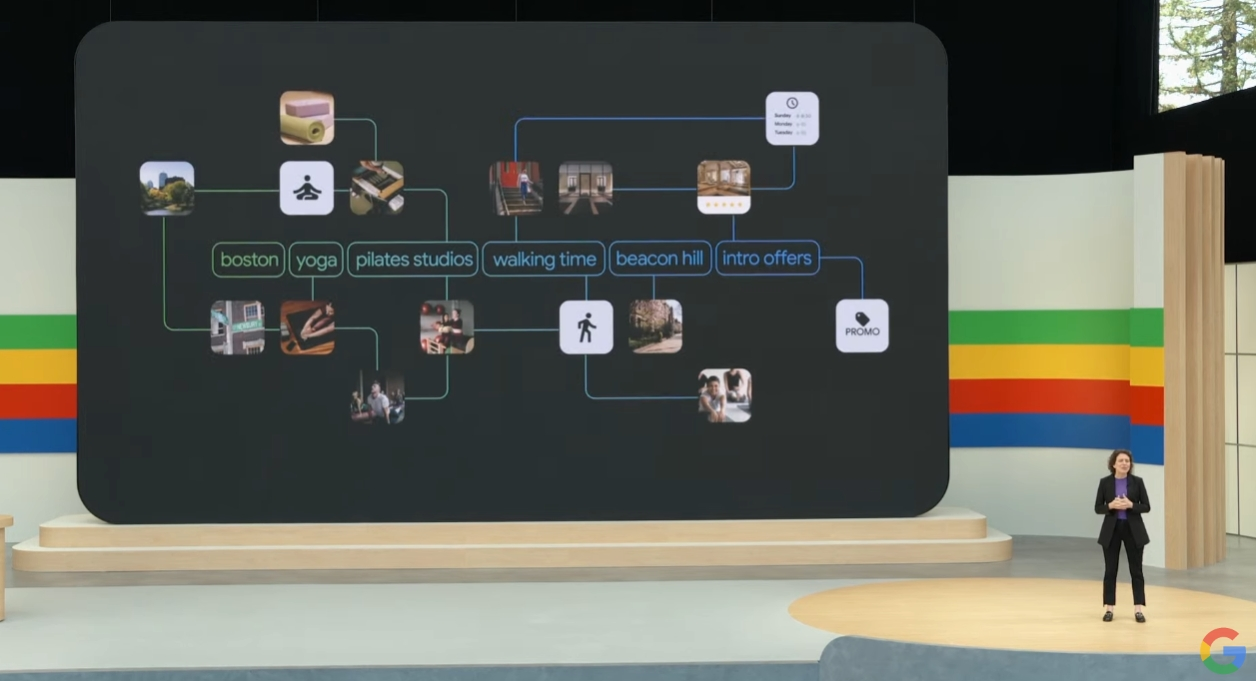
谷歌搜索业务负责人Liz Reid开始具体介绍AI Overviews功能。Reid表示,在进行搜索时,搜素引擎具备多步骤推理的能力,例如寻找一个瑜伽教室,同时展示新手优惠报价,和距离特定位置的步行时间。这个AI搜索引擎助手,还能介绍食谱、安排行程,以及接受视频形式的提问(例如视频中的相机怎么使用)。

在办公套件Workspace方面,谷歌将逐步推出总结、邮件Q&A,以及智能回复等功能。
谷歌Gemini总经理Sissie Hsiao介绍了Gemini App的更新。与周一的OpenAI一样,从今年夏天开始,Gemini也将支持语音实时交互,同时今年晚些时候还将上线实时视频交互功能。未来几个月内,谷歌也将推出类似于GPTs的自定义AI助手功能,叫做Gems。这个AI助手的亮点,将是能与“谷歌全家桶”进行交互。

Hsiao再次强调了Gemini的长上下文窗口——能够一次性处理整整1500页的文件,或3万行代码、1小时视频。不同的载体也能混同一起提交给聊天机器人。她再次强调,今年晚些时候上下文窗口将翻倍至200万Tokens。

安卓生态系统的负责人Sameer Samat登台,他将讨论今年安卓系统实现的“三大突破”,分别是“画圈圈搜索”、Gemini手机AI助手,第三是在手机本地运行的AI。
谷歌表示,今年晚些时候,能够在本地运行的多模态Gemini Nano模型将登陆Pixel手机,意味着手机将能通过文字、图片、视频、音频,理解用户的世界。举例而言,在听到“帮你把钱转到安全账户”这样的诈骗电话时,手机会自动弹出诈骗警告。整个过程都是在本地运行,不会引发隐私泄露。


谷歌披露大模型API的最新定价,其中Gemini 1.5 Pro定价为7美元/100万Tokens,12.8K上下文窗口的版本定价为3.5美元/100万Tokens;而Gemini 1.5的起售价为0.35美元/100万Tokens。

对于在今年二月刚刚推出的轻量级开源模型Gemma,谷歌宣布推出视频语言模型PaliGemma,并将会在6月推出Gemma 2。相较于第一代模型只有20亿和70亿的参数量,第二代开源Gemma的参数量能达到270亿。


作为发布会最后的彩蛋,谷歌CEO皮查伊最后用Gemini总结了今天的发布会稿子里总共提了多少次AI——120次。当然,这并不包括皮查伊问完这个问题后,又唤了几遍AI。


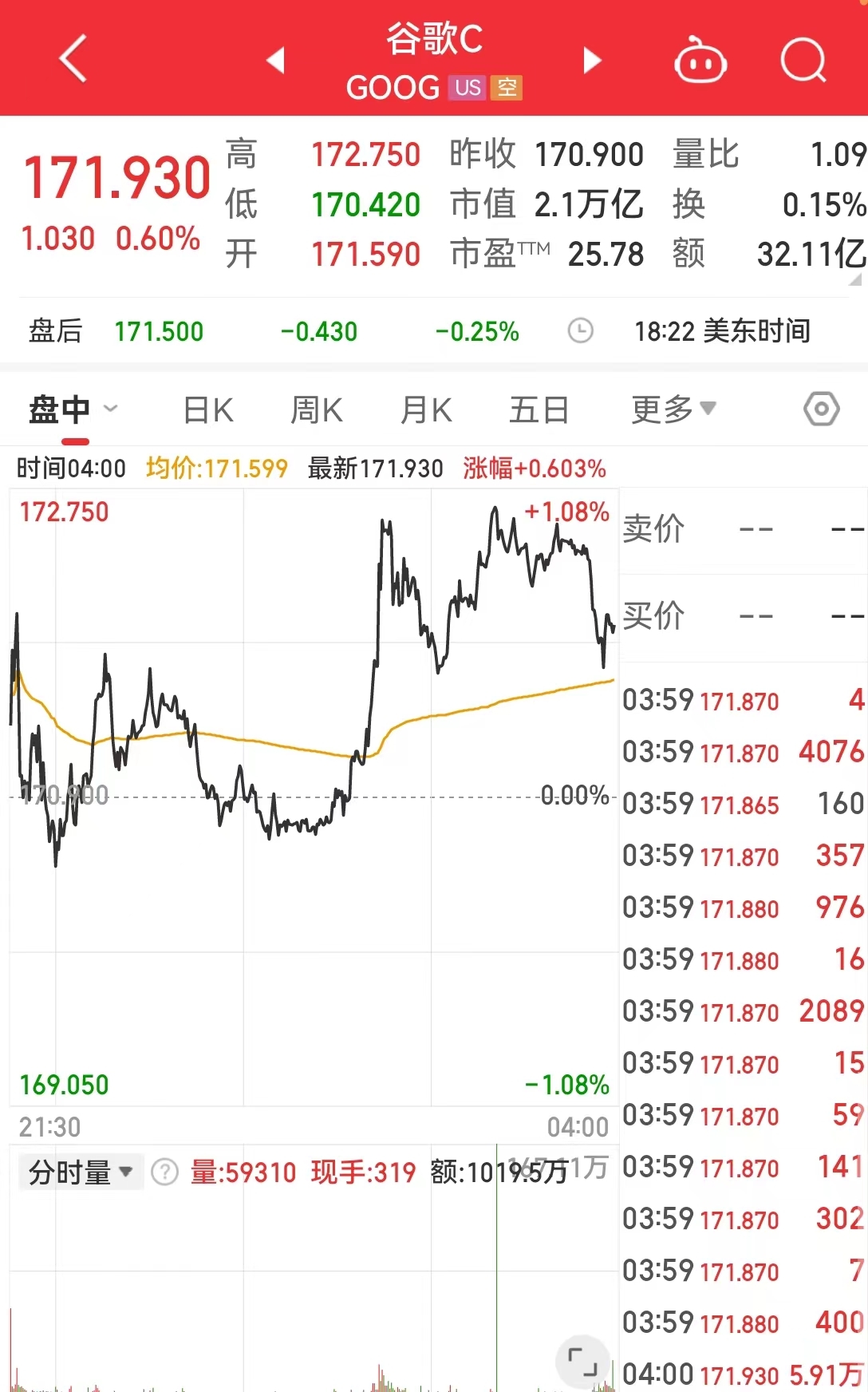
截至当地时间5月14日收盘,谷歌报171.93美元,涨幅0.6%,市值2.1万亿美元。
每日经济新闻综合公开资料
以上就是本篇文章【谷歌放大招,AI搜索引擎来了,发布最强AI模型!发布会现场:总共提了120次AI、视频模型登场......】的全部内容了,欢迎阅览 ! 文章地址:http://syank.xrbh.cn/quote/7357.html 行业 资讯 企业新闻 行情 企业黄页 同类资讯 网站地图 返回首页 迅博思语资讯移动站 http://kaire.xrbh.cn/ , 查看更多