PV、UV和IP是网站流量分析中常用的指标,它们分别表示以下含义:

- PV(Page View):页面浏览量或点击量,即网站所有页面被访问的总次数。每打开或刷新一个页面,PV就会增加一次,多次打开或刷新同一页面则浏览量累计。PV反映了网站用户访问的网页数量,是衡量网站流量的重要指标之一。
- UV(Unique Visitor):独立访客数,指访问网站的独立用户数。一天内同一访客多次访问只计算一次。可以理解成访问某网站的电脑的数量。网站判断来访电脑的身份是通过来访电脑的cookies实现的。如果更换了IP后但不清除cookies,再访问相同网站,该网站的统计中UV数是不变的。
- IP(Internet Protocol):独立IP数,指访问网站的IP地址数量。如果多个用户共用一个IP地址,也只算作一个IP。IP反映了不同IP地址的用户浏览网站的数量,是另一个衡量网站流量的重要指标。
这三个指标之间的关系是:一个访客(UV)可以产生多次页面浏览(PV),每产生一次页面浏览,PV+1。多个访客(UV)可以使用相同的IP地址访问,一个IP地址只计算一个独立IP(IP)。PV和UV的关系是,PV = UV × 平均页面浏览量。PV和IP的关系是,PV ≈ IP × 平均页面浏览量。
我们说的小网站,是一个月的流量在几百到几千之前,还属于一个增长期的网站,如何预估出他网站的流量。拿我自己的一个网站举例子,目前一个月搜索流量大概是50。我们看下已有的预估方法。
我们最长用的快速预估网站流量的方法,就是安装similar web的插件,但是similar web插件在小流量网站的流量统计预估非常不准。基本都是类似下面这种趋势,一个月几k,但是实际这个网站可能一个月100的访问量都没有。例如我自己的一个站点,目前一个月的Google搜索来的流量大概50左右。下面展示就是几千了。
sumrush估算网站流量的原理,是根据关键词的预计流量再按照你的关键词排名计算出来的。这个就很依赖你网站排名的关键词,在sumrush 词库的丰富度。很多中文关键词,sumrush 收录的并不好,所以小网站的流量通过这种方式计算也不合理。还是我自己的一个网站,sumrush 显示无流量。
最近看了一个叫做香菇肥牛的博客,感觉他的思路非常好。原理是通过谷歌的核心网站指标的数据分析的。谷歌浏览器会在用户访问每个网页的时候,将响应时长等网站指标上报到谷歌。待谷歌收集到200个访问/月,就会展示该网站的对应的移动端、PC端核心网站指标。
关键点在于,200个访问/月这个数值,我们可以根据谷歌是否展示该数据,推算出这个网站目前的访问量。
计算方式:
- 谷歌浏览器在全球占有约60-70%的市场占有率,我们简单计算就算60%吧。 如果谷歌收集了200个访问,那么就代表这个网站应该有200/0.6= 333次左右的访问。
- 针对小网站,一般移动端流量占比更低(这个原因我还没有弄的很清楚,可能跟谷歌自身的算法有关),有占比10-20%左右,我们按照15%预估。那么如果谷歌展示了移动端的核心指标,就代表移动端收集了200次+访问,所有浏览器的移动端应该有333次访问,移动端流量占比15%。那么整个站点应该有2200的流量
总结:如果只展示电脑端数据,不展示移动端,那么网站流量应该在300-400左右。如果展示了移动端,就代表网站实际有2000+的流量。
还是上面的那个站点,每个月访问50左右。谷歌就显示没有收集到数据,代表流量低于300/月。
首先他假设了移动端流量占整个网站的10%到20%。但是实际情况是不同类型的网站,这个占比不一定相同。
然后浏览器的市场占有率计算的也不准确,例如谷歌因为在中国大陆的限制,在简体中文网站流量占比就不准确。但是用来分析国外的网站还是非常好用的。
随着互联网的发展,越来越多的品牌注重线上推广,短信、社群,以及各种新媒体平台等成为推广的主要阵地,同时短链接也成为线上推广使用频率最高的工具。
某公司在一次产品推广活动中使用了短链接进行推广,并希望通过数据统计功能来跟踪和评估活动效果。然而,他们发现推广过后,无法正确访问和查看链接的数据统计,给活动效果的评估和优化带来了很大的不便。
1)无法准确评估推广效果:由于无法查看数据统计,该公司无法准确评估推广活动的效果。缺乏点击量、转化率等关键指标的数据支持,他们无法知道推广活动的真实效果如何,无法确定活动是否达到预期目标。
2)目标受众特征不清晰:缺乏数据统计,该公司很难了解推广活动的目标受众特征和行为习惯。他们无法确定哪个受众群体对产品感兴趣,无法精准定位目标受众并针对性地进行推广,导致推广效果可能无法最大化。
3)难以进行活动追踪和分析:由于无法访问数据统计功能,该公司无法跟踪和分析不同渠道或内容的推广效果。他们无法了解哪个平台或广告位的点击量最高,无法确定哪些推广策略更为有效,无法进行深入的推广活动分析。
如果不想遇到类似问题,建议大家选择有数据统计功能的短链工具,比如C1N短网址。
C1N短网址,支持长链接一键缩短,同步生成二维码,支持实时查看短链访问数据,包括pv、uv、ip数、用户地域分布、用户设备构成、用户访问环境等,并及时生成用户画像分析,数据实时刷新,支持历史数据跟踪对比,推广者可快速了解推广活动最新情况,掌握客户行为数据,以进行更加有效的定制营销策略,并实现精准营销。
具体操作步骤很简单,如下:
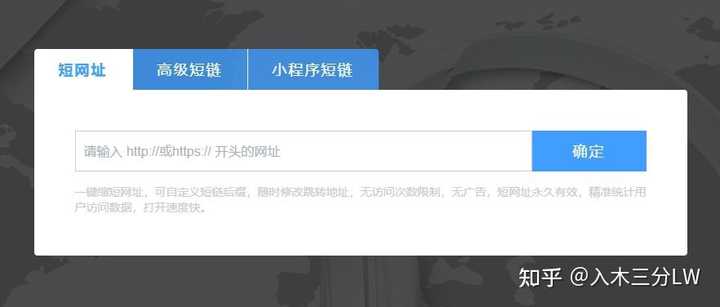
第一步:登录C1N短网址(http://c1n.cn),将要缩短的长链接复制到文本框内,然后点击【确定】,即可得到缩短后的链接。
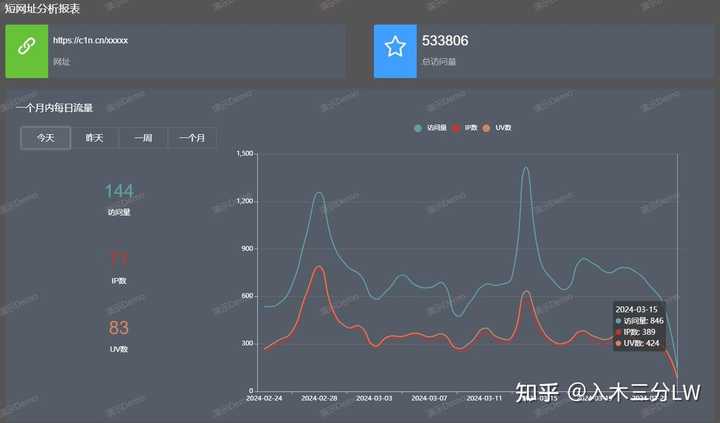
下面我们来具体说一说,每个菜单栏的数据代表什么:
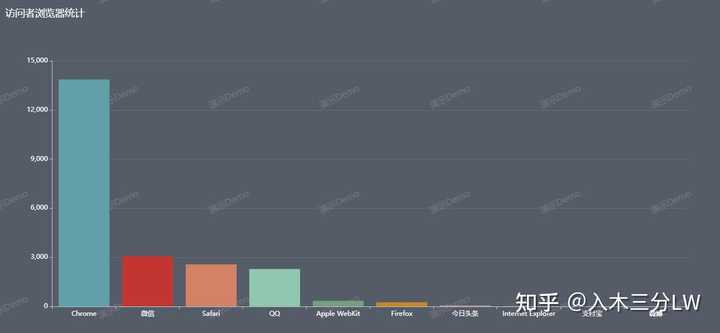
C1N短网址平台提供了多维度的数据统计,以此为基础可以生成用户画像,方便企业了解推广效果、优化决策依据、精准定位目标受众,从而降低推广成本,提升推广效果。
除此之外,还支持同步生成动态二维码,批量生成、API生成,支持小程序生成为短链。支持修改短链源网址与有效期,自定义短链接。
Redis INCR 命令
> SET page_view_count 100
OK
> INCR page_view_count
(integer) 101这种工具有很多,比如百度统计,51拉等等,而且都是很成熟的产品了。
cnzz,51la,bd,Google Analytics 统计它们都提供了开发接口\API接口,可以在页面里面埋点,触发事件统计,有详尽的报告。
51la:
51.LA网站统计V6bd:
Tongji API用户手册 · Tongji API用户手册如果条件允许, 可以使用Google Analytics, 它非常棒, 支持各种自定义。
https://developers.google.com/analytics/devguides/collection/ga4/events?hl=zh-cn&client_type=gtag如果想要一个新型的统计, 也可以看一下微软的这个:
Microsoft Clarity官网,微软推出的永久免费的行为分析工具,可帮助您了解用户与网站的交互。通过使用 Clarity 强大的分析工具,您可以为您的客户和业务增强您的网站。 - 无峰网址导航当用户在Similarweb的一个无门槛的免费工具上登陆后,他们会被引导去进一步探索Similarweb的所显示出来的数据。挑战在于不同的用户的需求其实是非常不同的,甚至用户决定为Similarweb付费的原因可能与他们最初来到Similarweb的原因都完全不同。

通过个性化的用户注册和偏好设置解决了这一难题。如果你是一个新用户,这个过程看起来像这样。
1、创建你的免费账户,这需要你的名字和姓氏,一个商业电子邮件和一个密码,也允许用户用他们的谷歌或linkedIn来注册。
2、完成基本信息输入,会提出一系列的问题,以便设置你的账户。
- 你的公司有多少人在工作?
- 你在哪个行业工作?
- 哪一个最能描述你的角色?
- 你的电话号码是多少?
3、体验特定的产品功能。鉴于我的回答和我进入网站的方式,个性化展现不同的功能让用户体验。
Similarweb实践PLG增长模式的关键启示
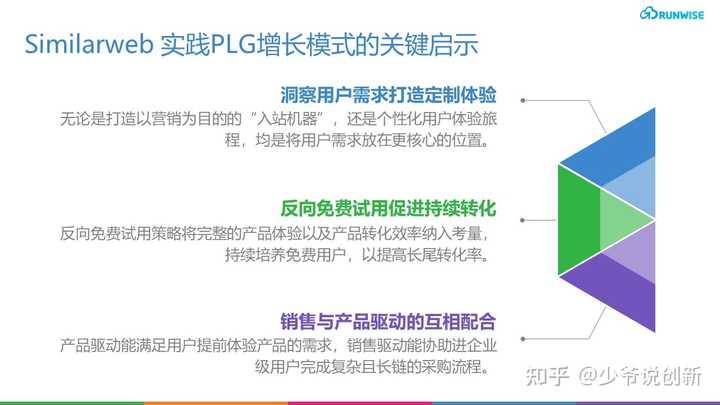
洞察用户需求打造定制体验:虽然产品主导可以理解为产品第一,但根据你的确切ICP来制定你的PLG战略是非常关键的。无论是打造以营销为目的的“入站机器”,还是个性化用户体验旅程,均是将关注用户画像以及用户需求放在更核心的位置。
反向免费试用促进持续转化:免费产品是测试产品市场需求的一个好方法。Similarweb在建立一个特定市场的新解决方案之前,通过免费的工具验证用户需求并决定付费产品是否值得投资。随后对自家的产品功能进行迭代升级,以了解特定行业的市场规模、搜索量和顶级关键词的功能,吸引合适的受众,同时搭配反向免费试用策略将完整的产品体验以及产品转化效率纳入考量,持续培养免费用户,提升长尾转化效率。
销售与产品驱动的互相配合:PLG远不止是一个产品战略。”他更像是一种文化。核心关键就是围绕潜在用户需求,并将其融入你所做的一切,”Maoz说。”这是一套不同的关键绩效指标。也是一种不同的产品开发方式。你必须愿意去尝试一些东西,并且接受失败”。 因此,产品驱动能满足用户提前体验产品的需求,销售驱动能协助进企业级用户完成复杂且长链的采购流程,这对满足用户需求这一核心理念来说,同样重要。
熊猫的博客一直采用的第三方的统计平台51La,虽说也很好用,但数据毕竟不在自己本地,第三方大概率会拿着你的数据进行算法优化、用户建模什么的。而今天介绍的Umami则是一款自部署的统计平台,采用Mysql或者Postgresql作为数据库,不需要担心数据被第三方使用。
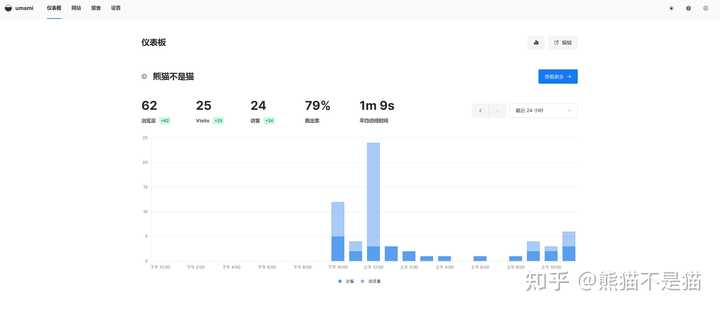
项目支持中文,界面整体简洁直观。网页主界面便是仪表盘,在这里可以看到你添加的网站信息。其中浏览量、来访、访客以及跳出率和平均访问时长都有,右边可以选择统计时间,这里只是一个大概的内容,会显示你所有添加的网站总览信息。
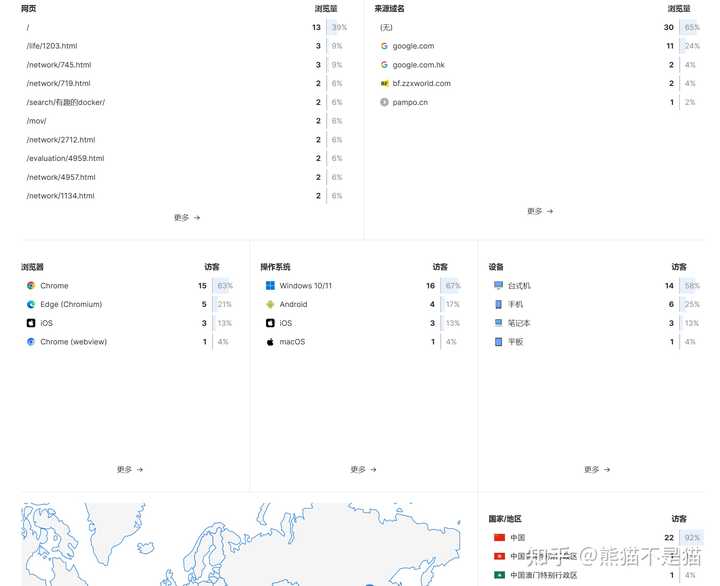
通过点击右边的查看更多,我们就能看到更为详细的统计界面。这里能看到访客访问的网页、来源域名、访客浏览器以及操作系统和设备,还能通过世界地图看到访客的来源地区。
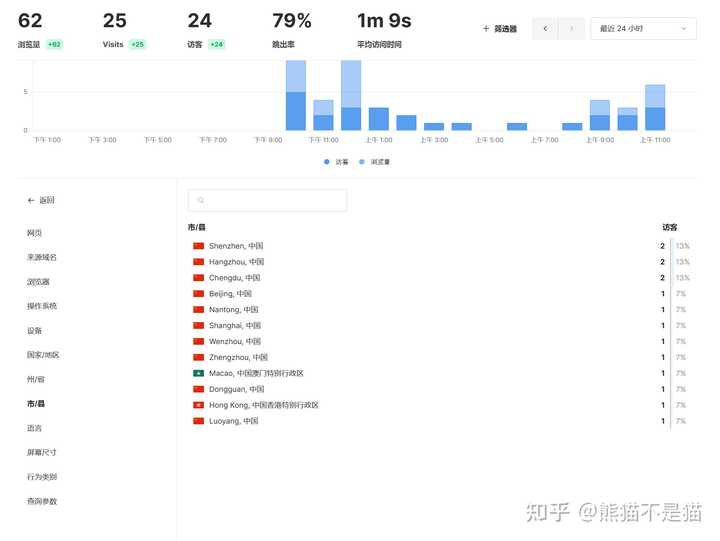
还有一点,在网站的更多信息中,通过点击更多可以看到更为详细的信息。例如精确到市级和县级的地址、屏幕尺寸、行为类别等等。
该项目的部署并不难,根据需求你可以选择Mysql或者Postgresql作为数据库,sql支持直接用MariaDB。这里我采用Postgresql部署,所以需要两个容器都部署。代码如下:
---
version: '3'
services:
umami:
image: ghcr.io/umami-software/umami:postgresql-latest
ports:
- "3000:3000"
environment:
DATAbase_URL: postgresql://umami:umami@db:5432/umami
DATAbase_TYPE: postgresql
APP_SECRET: replace-me-with-a-random-string
depends_on:
db:
condition: service_healthy
restart: always
healthcheck:
test: ["CMD-SHELL", "curl http://localhost:3000/api/heartbeat"]
interval: 5s
timeout: 5s
retries: 5
db:
image: postgres:15-alpine
environment:
POSTGRES_DB: umami
POSTGRES_USER: umami
POSTGRES_PASSWORD: umami
volumes:
- umami-db-data:/var/lib/postgresql/data
restart: always
healthcheck:
test: ["CMD-SHELL", "pg_isready -U $${POSTGRES_USER} -d $${POSTGRES_DB}"]
interval: 5s
timeout: 5s
retries: 5
volumes:
umami-db-data:
随后我们打开SSH端口,使用SSH工具连接上群晖之后cd到docker-compose文件的目录下,输入docker-compose up -d启动容器。(如有报错,重新启动一下即可)
此时项目就完成了,但要实现统计自己网站还需要进行设置。首先我们需要将项目反代一下,这里不管是使用lucky还是群晖自带都可以,我这里图方便直接用群晖自带的反代服务器。
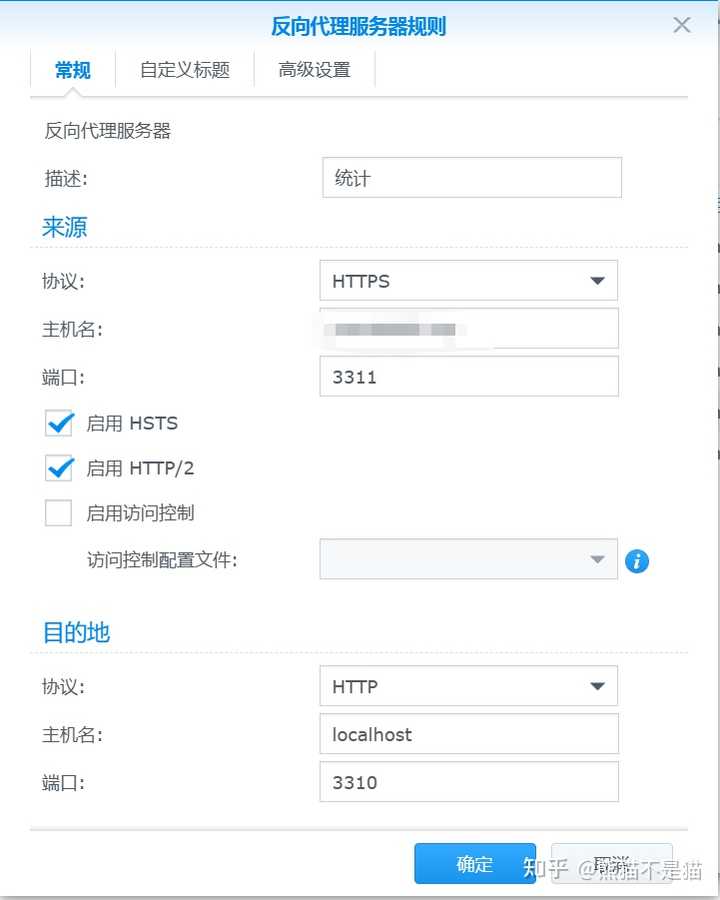
这时候再有人访问你的网站,Umami便会记录下他的所有行踪了。
非常不错的项目,自部署的统计平台数据均在本地,没有第三方偷跑的风险了。个人觉得这种隐私性较强的东西,还是部署本地要好一点。
以上便是本期的全部内容了,如果你觉得还算有趣或者对你有所帮助,不妨点赞收藏,最后也希望能得到你的关注,咱们下期见!

本文首发于我的个人博客Sun Blog
Umami 的官方仓库地址:umami-software/umami: Umami is a simple, fast, privacy-focused alternative to Google Analytics. (github.com)
Umami 需要数据库,支持 postgresql、mysql 等数据库,这里我们使用 vercel 提供的 postgresql 数据库服务。
选择 Postgres
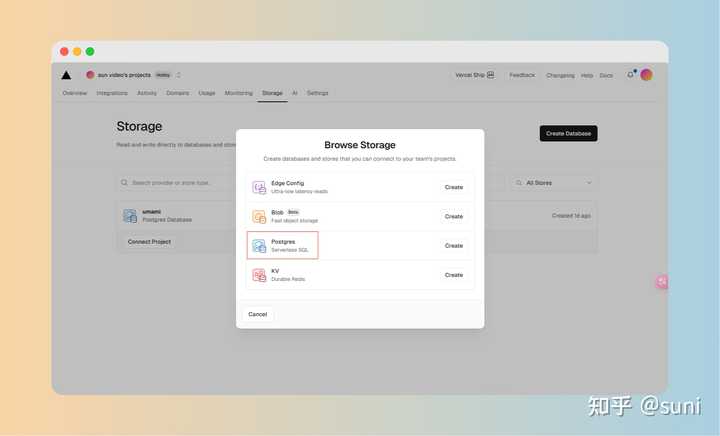
在 Environment Variables 中添加环境变量
点击 Deploy,等待部署完成即可,大约需要两分钟。部署完成后会显示 Congratulation 页面,点击右上角 Go to Dashboard 可以看到 vercel 提供的访问域名。
首先,明确你需要收集和分析哪些数据。这些数据通常包括:
• 访问量:如页面浏览次数(Pageviews)、唯一访客(Unique Visitors)、会话(Sessions)。
• 用户行为:如页面停留时间、点击事件、跳出率(Bounce Rate)。
• 流量来源:如直接访问、搜索引擎、社交媒体、外部链接等。
• 用户设备信息:如操作系统、浏览器类型、设备类型(移动/桌面)。
• 地理位置:用户的地域分布情况。
你可以选择以下两种主要方式之一来实现流量统计:
• 自建流量统计系统:完全定制化,但需要更多的开发时间和资源。
• 使用第三方工具:快速集成,如 Google Analytics(免费),但定制化程度有限。
2.1 自建流量统计系统
如果选择自建系统,以下是开发流量统计系统的主要步骤:
1. 数据收集
• 前端数据收集:在每个网页中嵌入 Javascript 代码来捕获用户行为数据。可以使用 AJAX 请求将这些数据发送到服务器。
• 后端日志记录:记录每个 HTTP 请求的详细信息,如时间戳、IP 地址、用户代理、访问的 URL 等。
2. 数据存储
• 使用数据库(如 MySQL、PostgreSQL、MongoDB)来存储和管理收集到的数据。设计合适的数据表来记录每个会话、用户和事件。
3. 数据处理与分析
• 使用脚本(如 Python、Node.js)定期处理和分析数据。你可以开发自定义的分析算法来计算关键指标(如 PV、UV、跳出率等)。
• 使用数据处理库(如 Pandas、NumPy)和分析工具(如 Jupyter Notebook)来处理数据。
4. 数据展示
• 使用前端框架(如 React、Vue.js)和图表库(如 Chart.js、D3.js)构建仪表盘,展示实时和历史数据分析结果。
• 开发 API 接口,使前端可以从数据库中获取处理后的统计数据。
5. 优化与扩展
• 根据需求扩展功能,如细化用户行为分析(点击流分析)、A/B 测试、转化漏斗分析等。
• 通过缓存、数据压缩等技术优化系统性能。
2.2 三方工具:使用 Google Analytics 进行流量统计
1. 创建 Google Analytics 账号:
• 访问 Google Analytics,创建一个新的账号和一个新的属性来跟踪你的网站。
2. 获取跟踪代码:
• 在 Google Analytics 中,导航到你创建的属性,找到跟踪代码(通常是一个 Javascript 代码段)。
3. 集成跟踪代码:
• 将跟踪代码添加到你网站的每个页面中,通常放置在 HTML 的 <head> 部分。例如:
<head>
<!-- Google Analytics -->
<script async src="https://www.googletagmanager.com/gtag/js?id=UA-XXXXX-Y"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'UA-XXXXX-Y');
</script>
<!-- End Google Analytics -->
</head>4. 定义自定义事件和目标:
• 根据需求,可以在特定用户行为(如按钮点击、表单提交)时触发自定义事件。例如:
// 在某个按钮点击时记录事件
document.getElementById('myButton').addEventListener('click', function() {
gtag('event', 'button_click', {
'event_category': 'Button',
'event_label': 'Homepage Button'
});
});
5. 查看和分析数据:
• 登录 Google Analytics 仪表盘,查看实时数据、用户行为报告、流量来源报告等。
Microsoft Clarity是由微软在2020年10月推出的一款免费网站分析工具,旨在帮助网站管理员深入理解用户在其网站上的行为。通过提供全面而详细的数据分析,Clarity使网站管理员能够准确了解用户的操作,进而优化用户体验并提高网站转化率。
- 用户会话重放:提供真实用户的会话录像,使管理员可以像观看视频一样了解用户的行为,识别问题和困难,以改善用户体验。
- 热力图:通过可视化显示用户在网站上的点击和滚动行为,帮助理解用户的关注点和兴趣区域。
- 点击地图:展示用户在页面上的点击位置,有助于优化页面布局和设计。
- 页面加载速度检测:检测页面加载速度并提供优化建议,以改善用户体验。
- 自定义事件跟踪:允许自定义设置和追踪特定的用户行为,如按钮点击次数或特定页面的访问量。
- 免费且易于使用:Clarity不仅免费,而且安装和使用都非常简单,适用于各种规模的网站。
- 功能重点:Clarity专注于用户体验,提供会话重放、热力图和点击地图等功能,而Google Analytics提供广泛的功能,包括流量和电子商务指标分析。
- 数据洞察:Clarity提供与用户体验相关的数据可视化(如点击、滚动等),而Google Analytics侧重于流量和转化率等指标。
- 流量限制:两者都适用于不同规模的网站,没有流量限制。
Clarity的推出,特别是其免费和开源的特性,为网站管理员提供了一个强大的工具,以深入了解用户行为,优化用户体验。与Google Analytics相比,Clarity提供了一种更直观的方式来观察和分析用户的实际操作,尤其是对于那些希望深入理解用户如何与网站互动的人来说,这一点非常宝贵。
综上所述,无论是独立使用还是与其他工具如Google Analytics结合使用,Microsoft Clarity都能为网站管理员提供宝贵的洞察,帮助他们提升网站性能,优化用户体验,并增加转化率。
先贴一段统计字母频数并输出的代码:
import matplotlib.pyplot as plt
from collections import defaultdict
def count_letters(text):
# 使用defaultdict来简化字典的初始化
letter_freq = defaultdict(int)
# 转换为小写并统计字母频率
text = text.lower()
for char in text:
if char.isalpha():
letter_freq[char] += 1
return letter_freq
def plot_letter_frequency(letter_freq):
# 字母按照频率排序
sorted_letters = sorted(letter_freq.items(), key=lambda x: x[1], reverse=True)
# 分离字母和频率
letters, frequencies = zip(*sorted_letters)
# 设置图形大小和分辨率
plt.figure(figsize=(12, 8), dpi=80)
# 创建条形图
plt.bar(letters, frequencies)
# 设置图表标题和坐标轴标签
plt.title('Letter Frequency in Text')
plt.xlabel('Letters')
plt.ylabel('Frequency')
# 旋转x轴标签以便更好地显示
plt.xticks(rotation=90)
# 显示图表
plt.show()
# 获取用户输入的文本
input_text = input("请输入一段英文文本: ")
letter_frequencies = count_letters(input_text)
# 绘制条形图
plot_letter_frequency(letter_frequencies)效果如下:(复制了一本小说里的一个小节)
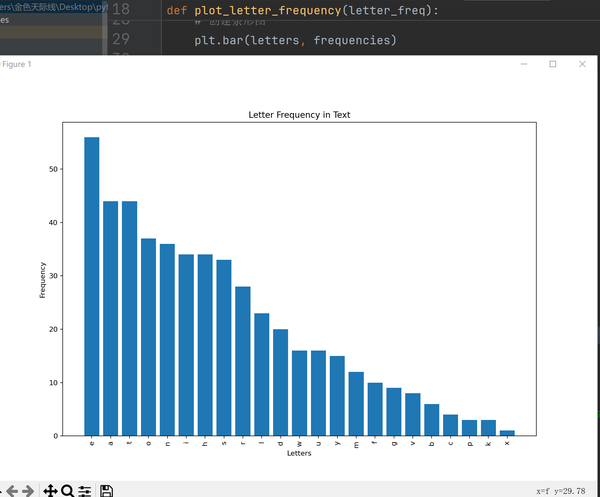
但如果要统计字数很多的文本,建议先把文本储存到docx文件,再要求读取指定路径里的docx文件,代码如下:
from docx import document
from collections import Counter
import matplotlib.pyplot as plt
import string
# 读取Word文档内容
def read_docx_file(file_path):
doc = document(file_path)
text = []
for para in doc.paragraphs:
text.append(para.text)
return ' '.join(text)
# 统计字母频数并排名
def count_letters(text):
# 移除标点符号,只保留字母
letters_only = ''.join(c for c in text if c.isalpha())
# 转换为小写以合并相同的字母统计
letters_only = letters_only.lower()
# 统计字母频数
letter_counts = Counter(letters_only)
# 根据频数排名
ranked_letters = letter_counts.most_common()
return ranked_letters
# 绘制字母频数图表
def plot_letter_frequency(ranked_letters):
letters, freq = zip(*ranked_letters)
plt.figure(figsize=(10, 15))
plt.barh(letters, freq)
plt.xlabel('Frequency')
plt.ylabel('Letters')
plt.title('Letter Frequency in DOCX File')
plt.show()
# 主函数
def main():
file_path = 'D:/草稿本\三天光明.docx' # 替换为你的DOCX文件路径
text = read_docx_file(file_path)
ranked_letters = count_letters(text)
plot_letter_frequency(ranked_letters)
if __name__ == '__main__':
main()如果
在当今数字化时代,网站流量统计对于优化网站性能和理解用户行为至关重要。然而,许多商业流量统计服务可能会让你感到预算紧张,尤其是当你刚刚起步时。好消息是,你完全可以手动搭建一个网站流量统计系统,不仅能节省成本,还能根据自己的需求进行定制。在这篇文章中,我们将探讨如何从头开始构建一个自定义的网站流量统计系统,帮助你掌握网站数据的全貌,无需依赖昂贵的第三方服务。
实施背景:
成品效果:
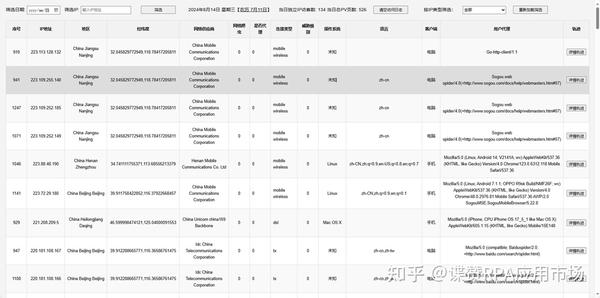
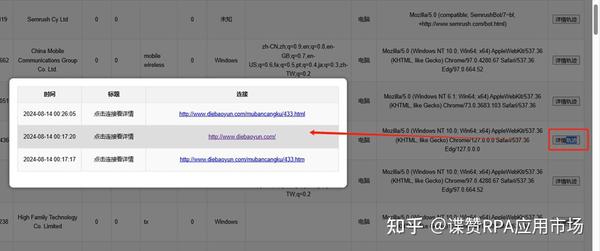
点击详情轨迹后:
功能说明:
1、记录:所有对网站产生任意一个请求的用户客户端或者请求发起端的信息,都会被记录;
2、记录:当前请求对应用户客户端的IP地址;
3、记录:IP对应的地区、经纬度、网络供应商名称
4、记录:对当前IP进行分析是否为爬虫、是否为代理、威胁等级;
5、记录:当前请求对应客户端的硬件操作系统、语言版本环境类型
6、记录:发起请求的客户端类型,是手机访问还是电脑;
7、记录:用户发起请求对应的浏览器user_agent信息;
8、记录:当前IP在24小时内的所有请求访问轨迹,全部归档至详情阅读窗口,并按顺序排列;
9、记录:当日独立IP访客请求数(包含用户与蜘蛛);
10、记录:当日总PV页数访客请求数(包含用户与蜘蛛);
11、支持:按日期查询每天的用户请求和蜘蛛请求;
12、支持:按指定IP查询任意天内的所有访问日志记录;
13、支持:按IP类型筛选,可以选择用户或者蜘蛛,来分别查阅数据;
14、支持:一键清理所有访客日志;
15、支持:时间与IP的多条件查询;
16、屏蔽:所有来源于脚本类的请求,比如python,防止被批量爬虫而导致服务器资源枯竭最终引起网站无法正常打开的问题;
实施代码如下:
1、检测PYTHON代码,并屏蔽请求代码:
<?php
// 检查用户代理是否包含 Python 或 requests 字符串
$user_agent = $_SERVER['HTTP_USER_AGENT'];
if (strpos($user_agent, 'Python') !== false || strpos($user_agent, 'requests') !== false) {
header('HTTP/1.1 403 Forbidden');
echo "Access Forbidden: 禁止通过 Python 或 requests 封装库环境来发送请求!";
exit;
}
?>2、访客请求统计并分析客户端数据及入库代码:
从下载手搓网站访客流量统计系统文件包:https://www.diebaoyun.com/jinengjiqiao/817.html
此压缩包里面一共有四个文件,分别如下:
fangketongji.php:是浏览访问记录的前端界面;可以在223行修改数据库配置文件路径;
fangkedata.php:是数据库的配置文件
database.php:是集成到网站页面里面去的统计获取代码,为了访问统计的更精准,可以直接将这个代码内容全部放在网站的原始数据库配置文件里面去;
visits.sql:是访客系统的数据库表结构,可以直接导出原始网站数据后直接使用即可,此SQL来源于本站的备份,可导出后,全部清空数据库即可;
在当今数字化时代,网站流量统计对于优化网站性能和理解用户行为至关重要。然而,许多商业流量统计服务可能会让你感到预算紧张,尤其是当你刚刚起步时。好消息是,你完全可以手动搭建一个网站流量统计系统,不仅能节省成本,还能根据自己的需求进行定制。在这篇文章中,我们将探讨如何从头开始构建一个自定义的网站流量统计系统,帮助你掌握网站数据的全貌,无需依赖昂贵的第三方服务。
实施背景:
点击详情轨迹后:
功能说明:
以上就是本篇文章【网站流量统计收费?绝对不可能!手搓一个网站流量统计系统】的全部内容了,欢迎阅览 ! 文章地址:http://syank.xrbh.cn/news/10399.html 资讯 企业新闻 行情 企业黄页 同类资讯 首页 网站地图 返回首页 迅博思语资讯移动站 http://kaire.xrbh.cn/ , 查看更多 点击拨打:
点击拨打: